
师资培训
国培、省培、1+X证书全方位提升教学水平

修改密码
本书特色:1、本书是“十四五”职业教育国家规划教材,内容契合“1+X”证书制度试点工作中的大数据应用开发(Python)职业技能高级证书考核标准,全书将理论与实战结合,注重任务案例的学习。2、本书坚持理实一体化的理念(理实一体化,就是理论与实践融会贯通),教材编写中,按照国家职业标准、职业技能鉴定标准,以技能训练为核心、理论知识够用为度作为人才培养的目标定位,以技能训练项目为主线,将理论知识按照实训的需要融入实训(技能训练)中,形成一体化项目模块。3、通过与行业企业专家和技术骨干交流,分析职业岗位(群)典型工作任务,准确对接职业标准,将自然语言处理工作中需要完成的各关联任务和所需的技能进行归纳整合,形成满足完成岗位(群)工作任务要求的典型工作,再将典型工作由易到难进行教学加工,紧密围绕《自然语言处理》课程中对学生的知识、能力、素质的要求,同时结合大数据与人工智能职业标准,开展以岗位职业技能为引领、项目或任务为载体,学生职业成长规律和职业技能培养为核心的理实一体化教材编写基本结构框架设计。4、案例、理论、算法和程序四位一体。本书始终以培养读者问题解决能力为宗旨,在各章中安排了丰富的实例,并且还包含一系列算法模型(n元语法模型、隐马尔可夫模型、Word2Vec表示、DM模型、DBOW模型、seq2seq模型),每种算法都提供了详细python代码和注释,方便在理论的基础上理解算法,帮助读者更直观地理解自然语言处理的理论、算法,并掌握利用相关技术和算法解决本领域实际问题的能力。5、课程思政融入案例。在案例选择中,注重对学生三观的正确引导,例如加强道德素质和法治素养的培养:通过提供合法的案例数据库,培养学生知识产权意识,提高学生学术道德素质和法治素养;通过科大讯飞发展等案例,展示中国目前蓬勃发展的自然语言处理技术,同时培养学生的爱国情怀、民族自信及创新意识,彰显“文化自信”; 通过实际案例训练,深化职业理想和职业道德教育,培养学生脚踏实地、主动求知、知难而进、不断创新、勇攀科学高峰的探索精神。6、资源齐备,便于学习:本书为教师和学生提供了相关的学习和教学资源用书,包括教学用PPT、案例的数据集和源代码、习题答案、微课等;每章还配有类型丰富的习题和案例,既方便教师授课,也可以帮助读者通过这些学习资源巩固所学知识。
内容简介:本书以Python自然语言处理的常用技术与真实案例相结合的方式,深入浅出介绍Python自然语言处理的基本内容。全书共12章,全部章节都包含了思考与练习题,通过练习和操作实践,帮助读者巩固所学的内容。
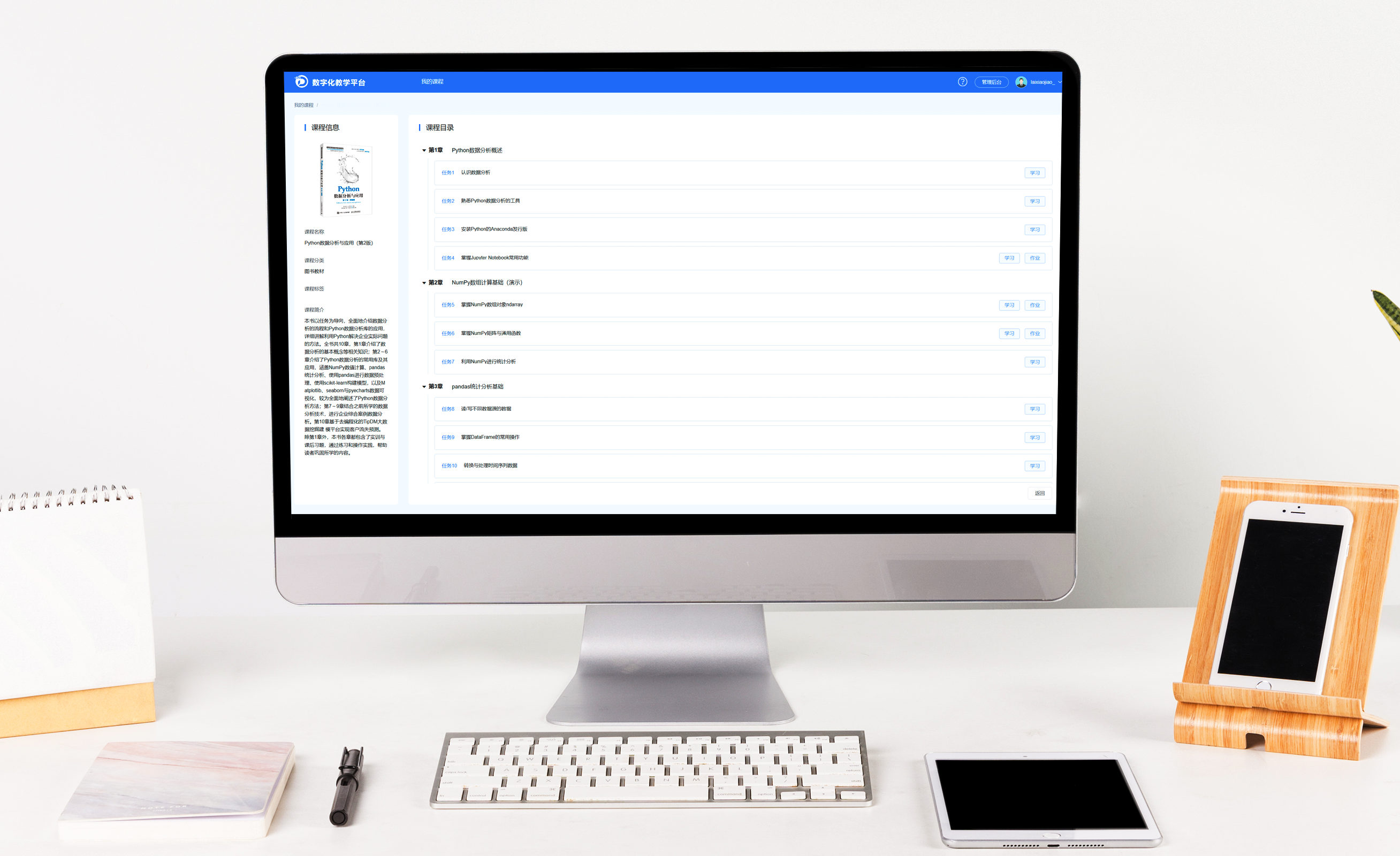
第1章绪论1
1.1自然语言处理概述1
1.2NLP基本流程1
1.3NLP的开发环境1
小结1
课后习题1
第2章语料库20
2.1语料库概述20
2.2语料库种类与原则20
2.3NLTK库20
2.4语料库的获取20
2.5任务:语料库的构建与应用20
小结20
实训20
实训1 构建语料库20
实训2 《七剑下天山》语料库分析20
课后习题20
第3章正则表达式48
3.1正则表达式48
3.2任务:正则表达式应用48
小结48
实训48
实训1 过滤《三国志》中的字符48
实训2 提取地名与邮编48
实训3 提取网页标签中的文本48
课后习题48
第4章中文分词技术61
4.1中文分词简介61
4.2基于规则的分词61
4.3基于统计的分词61
4.4中文分词工具jieba库61
4.5任务:中文分词的应用61
小结61
实训61
实训1 使用HMM进行中文分词61
实训2 提取文本中的高频词61
课后习题61
第5章词性标注与命名实体识别92
5.1词性标注92
5.2命名实体识别92
5.3任务:中文命名实体识别92
小结92
实训 中文命名实体识别92
课后习题92
第6章关键词提取116
6.1关键词提取技术简介116
6.2关键词提取算法116
6.3任务:自动提取文本关键词116
小结116
实训116
实训1 文本预处理116
实训2 使用TF-IDF算法提取关键词116
实训3 使用TextRank算法提取关键词116
实训4 使用LSA算法提取关键词116
课后习题116
第7章文本向量化142
7.1文本向量化简介142
7.2文本离散表示142
7.3分布式表示142
7.4任务:论文相似度计算142
小结142
实训142
实训1 实现基于Word2Vec的新闻语料词向量训练142
实训2 实现基于Doc2Vec的新闻语料段落向量训练142
实训3 使用Word2Vec和Doc2Vec计算新闻文本的相似度142
课后习题142
第8章文本分类与聚类168
8.1文本挖掘简介168
8.2文本分类常用算法168
8.3文本聚类常用算法168
8.4文本分类与聚类的步骤168
8.5任务:垃圾短信分类168
8.6任务:新闻文本聚类168
小结168
实训168
实训1 基于朴素贝叶斯的新闻分类168
实训2 食品种类安全问题聚类分析168
课后习题168
第9章文本情感分析188
9.1情感分析简介188
9.2情感分析的常用方法188
9.3任务:基于词典的情感分析188
9.4任务:基于文本分类的情感分析188
9.5任务:基于LDA模型的情感分析188
小结188
实训188
实训1 基于词典的豆瓣评论文本情感分析188
实训2 基于朴素贝叶斯的豆瓣评论文本情感分析188
实训3 基于Snownlp的豆瓣评论文本情感分析188
实训4 基于LDA的豆瓣评论文本情感分析188
课后习题188
第10章NLP中的深度学习技术208
10.1循环神经网络概述208
10.2RNN结构208
10.3深度学习工具208
10.4任务:基于LSTM的文本分类与情感分析208
10.5任务:基于Seq2Seq的机器翻译208
小结208
实训208
实训1 实现基于LSTM的新闻分类208
实训2 实现基于LSTM的携程网评论情感分析208
实训3 实现基于Seq2Seq和GPU的机器翻译208
课后习题208
第11章智能问答系统253
11.1问答系统简介253
11.2问答系统的主要组成253
11.3任务:基于Seq2Seq的智能问答系统253
小结253
实训 基于Seq2Seq模型的闲聊机器人253
课后习题253
第12章基于TipDM数据挖掘建模平台实现垃圾短信识别280
12.1平台简介280
12.2实现垃圾短信识别280
小结280
实训 实现基于朴素贝叶斯的新闻分类280
课后习题280
| 文件名 | 文件大小 | 上传时间 | 操作 |
|---|---|---|---|
| 《Python中文自然语言处理基础与实战》实训数据 | 50.36MB | 2023-03-31 | 下载 |
| 《Python中文自然语言处理基础与实战》PPT | 11.77MB | 2023-03-31 | 下载 |
| 《Python中文自然语言处理基础与实战》课程大纲 | 39KB | 2023-03-31 | 下载 |
| 《Python中文自然语言处理基础与实战》教学进度表 | 24KB | 2023-03-31 | 下载 |
| 《Python中文自然语言处理基础与实战》教案 | 291KB | 2023-03-31 | 下载 |
| 《Python中文自然语言处理基础与实战》习题数据和答案(1) | 90.30MB | 2023-11-29 | 下载 |
| 《Python中文自然语言处理基础与实战》虚拟环境使用说明(1) | 436KB | 2023-12-11 | 下载 |
| 《Python中文自然语言处理基础与实战》正文数据和代码(2) | 61.88MB | 2025-03-17 | 下载 |
Copyright © Guangzhou TipDM Intelligent Technology Co.,Ltd. 广东泰迪智能科技股份有限公司 ICP备14098620号-4










 老师交流Q群
老师交流Q群 关注 "官方公众号"
关注 "官方公众号"